Skills every SEO specialist should have
A successful SEO expert knows and applies techniques and methods from multiple IT disciplines that help him to collect, process and analyze data. He works more productively, faster and achieves better results. He does not need to be an absolute expert in each discipline, but to apply basics that make it easier for him to beat the competition.
I often look marketing job offerings because I want to see how Internet marketing (read: SEO) is viewed by the startup owners, various companies and their HR managers. I am interested to read job descriptions, and especially the conditions that candidates have to fulfill. There is no difference between domestic and foreign job postings - companies that know what SEO is have no problem defining the conditions. Firms that think they know SEO- they wander around and miss the point.
Like a thousand times before, once again it is shown that the Internet marketing community must first educate the public, and then offer their services. Otherwise, we will be treated as spammers or snake-oil salesmen.
So let's get started. Keep in mind that I will update this text over time.
HTML & CSS
Understanding HTML code is the basis of SEO optimization
HTML is an alphabet of every SEO job. Necessary technical knowledge without which you should not dive into optimization. You will work with meta tags, rel canonicals, internal architecture, HTTP responses and hundreds of other elements on a daily basis. Google bot "examines" your site through the DOM, so you also need to understand the DOM (and the source code of the page). If you are working on a multilingual website, you must know how to apply hreflang, if you ou have a site with pagination then apply rel prev/next and canonical etc. There are a million things that you do in HTML. You do not need to write an absolutely valid code, but it must be semantically correct.
A little about CSS
Why is CSS important for SEO? Aside the styling of HTML, you have to optimize the "delivery", speed and usability of the site on multiple devices (desktop, tablet, mobile). Not only you need to distinguish classes from IDs, but you also know how to cope with CSS so that it does not block rendering of the page, or how to optimize code with a use of variables, nesting and compiling of the CSS.
Google algo easily catches CSS manipulations so please try to avoid possible problems. Do not block crawl of CSS and JS from the robots.txt file.
Bonus chapter – Microdata, JSON-LD and Schema.org
"Rich snippets" mark-up content in order to give a semantic meaning or description of what a particular element represents (logo, company name, address, image, price, picture ...). Useful for visitors, and important for search as Google grabs data and often displays... "rich snippets". Many do not care about this this mark-up, and you who spend the time will be rewarded with higher CTRs, better positions and greater trust by your visitors.
See the example below.
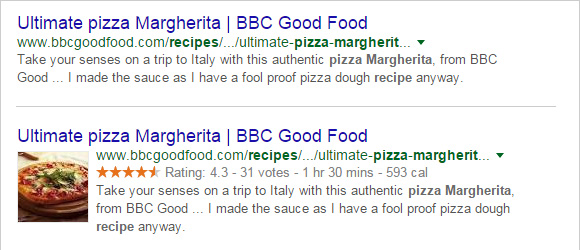
Same content on Google results without and with microdata embedding HTML code
As we see on the example below (pizza margherita recipe), the photo No2 shows some additional information and will probably attract more clicks than the "regular" result when we do not apply "rich snippets" code. Directly on Google's SERP we can see:
- Photo of the dish
- Users' reviews
- The number of people who rated the recipe
- Preparation time
- Caloric value
The real challenge is, of course, to provide support to developers when implementing schema.org mark-up in our ecommerce systems, WordPress includes filters and loops. You should be aware how PHP works and how some elements are rendered on the front-end.
Links and resources for "rich snippets":
Google Structured Data Testing Tool
Schema.org vocabulary
"Rich snippets: Everything you need to know" by BuiltVisible
Javascript
You do not need to code, but you need to understand whether certain content is available to search bots for crawling and indexing. Javascript provides many nice and useful things on the web, but forget about indexing and ranking if the spider bot needs to click somewhere, input something in the text field, or do an action that gives back dynamically generated content. With the help of information from Webmaster Tools, we can see the ways in which Console renders the page. SEO specialist should be able to identify problems created by Javascript. Luckily, Google became much smarter so system can follow javascript redirects, links and indexes dynamic content (but now always).
Once again about blocking Javascript in robots.txt file
Case No1: Unblocked JS & CSS
HTML + JS + CSS=Desktop website (if being visited by a regular Google bot)
HTML + JS + CSS=Mobile website (if being visited by a Google Mobile bot).
So everything works fine, each element is in place and nothing breaks down regardless of which search engine robot opens the page.
Case No2: Blocked JS & CSS
HTML + JS + CSS=A very bad desktop site in both cases
Google is blind, system can not properly render the page and let's say validate your site as "mobile-friendly".
Regex or regular expression
Regex is a set of rules that define a particular pattern, helping us to process or analyze through a large batches of data. So, set the regex rule, apply the operation and save yourself a lot of time. There are numerous applications, starting from defining filters in Google Analytics, processing large amounts of keywords in a text editor or Excel, writing code for 301 redirects when migrating a site through a .htaccess file.
Although at first glance it seems complicated, you can quickly pick-up regex, so I really recommend you start playing with it.
For example, the following code in the .htaccess file creates a permanent 301 redirection from non-www to the www domain.
RewriteEngine On
RewriteCond %{HTTP_HOST}!^www\.
RewriteRule ^(.*)$ http://www.%{HTTP_HOST}/$1 [R=301,L] The above code literally says: if the HTTP host does not start with www. then apply a rule that redirects it to the "www" version.Regex !^www\. captures any URL that does not start with "www."
Put the following regex in the "Keyword Report" in the analytics and you will get a list of keywords that have three words.
^[^\.\s\-]+([\.\s\-]+[^\.\s\-]+){2}$ Use the following "Find / Replace" in Notepad ++ and the keyword list separated by commas, will be transformed into the set of keywords with each phrase in the new line.
Find: ,\s
Replace: \r\n The Internet is full of useful articles and regex is generally easy to learn. My recommendation is to look at the following links.
Regex for Google Analytics
Regular Expressions Guide
Server side setup, mostly through the .htaccess file
When it comes to technical SEO, this is not an essential skill, but it helps if you know how to override some server settings using the .htaccess file.
In 99% of cases you will work on redirectories and rewriting URLs. For example: adding or removing the trailing slash at the end of a URL, migrating a site to a new domain, 301 redirecting certain URLs etc.
The combination of regex and htaccess rules gives you powerful results that improve the SEO of your site, but small errors in writing the code can cause real headaches.
I recently helped the client to solve a very specific problem when a developer wrote a rule that overwrites the uppercase to lowercase in URLs. So, if we have a URL /Seo-Skills rule will rewrite URL to /seo-skills.
This solved the duplicate content issues on the site, because the same content was available through two URLs. However, the problem arose when the htaccess rule changed the upper and lower case letters of "gclid" parameter of the Google AdWords campaigns.
The URL was rewritten in the following manner:old URL: /Seo-Skills?gclid=As1TRksn
new URL: /seo-skills?gclid=as1trksn
The parameter ?gclid=As1TRksn should not be modified because the AdWords system depends on the exact character string (including uppercase and lowercase). For the next eight days, Google Analytics did not have precise PPC campaign data.
Solution was to modify the .htaccess rules so that URL rewritting is ignored if there is a gclid parameter.
So, be careful with server-side settings.
Excel
Tool No1 in digital marketing, if you ask me. When so much data is available to us, it's worth knowing how to process it. Most internet marketing tools and services offer the ability to export data to CSV or XLS files (AdWords, Analytics, Facebook Ads manager, MOZ, Semrush, Ahrefs ...), and then the real fun in Excel starts.
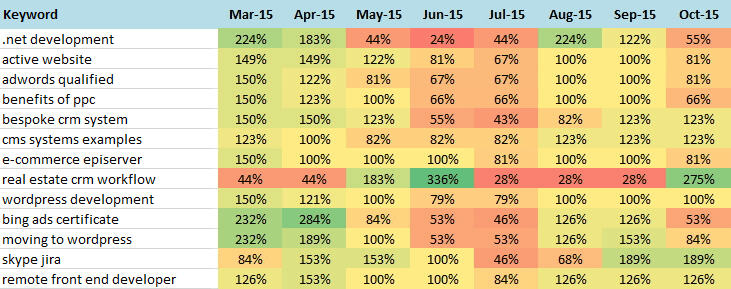
Market Analysis: Monthly search trends
My suggestion is to first master the table formatting, importing data (XML and CSV), pivoting tables, advanced filtering and learning as many functions as possible.
The above example gives a visual representation of the question: When are searches happening during the year? It's easy to see the that March and April are very intense months when you need to boost your AdWords campaigns, while for example June or October are not too strong. It took me few seconds to get such a report by exporting search terms from the Google Keyword Planner and playing a little bit in the Excel.
Begin learning Excel from basics like deleting duplicate entries, determining the number of characters (useful when writing text ads for Google AdWords or meta tags for site pages), merging content of multimple columns into a single string, trim the empty space at the end of the cell's content.
Later move on with learning pivot tables, because only then can you get a deeper understanding of the relationship between certain metrics and dimensions and identify the places that need to be corrected or heavily exploited during marketing campaigns.
If you want to learn a lot of useful Excel tricks in less than an hour, then be sure to look at the following clip.
There is no point of naming what you can do in Excel, so I advise you to search for YouTube channels and other online resources where you can find out more info.
Bonus tip: look at SEO Tools for Excel, an Excel add-on that can replace a large portion of paid tools for on-site SEO analysis.
Web scraping
Scraping represents the data extraction from web pages into local databases or tables. To be clear at the beginning, I am writing here about the "white hat" data extraction. The basic methos is extracting publicly available information from HTML, RSS feeds, and when you master that process, the logical continuation is the use of APIs.
How does scraping benefit us working in Internet Marketing?
First of all, we capture a large amount of data for free: meta tags, keywords, ideas for blog articles, the number of Facebook likes of a page in question, the number of Twitter subscribers, the prices of your competitor's products...
An brief example: we find the sitemap.xml file of our competitor, we import it into Google Sheets, and then for each URL (which is in column A) we scrape the meta title in column B. If the site has 50 pages, we get all meta title tags in less than one minutes, if the site has 1000 pages then maybe about 5 minutes. Imagine manually copying 1000 meta tags, how long would it take for such a job? Only thing you need to do it to enter the following function in cell B1:
=ImportXML(A1, "//title/text()") Click here and see what the result looks like. For faster processing, the number of URLs is limited to 5.
There are lits of scraping methods, the above example is the implementation of the ImportXML function developed by Google. There are WordPress plug-ins that easily extract RSS feeds, there is a fantastic Chrome extension for scraping from the Developers Tools, and there is already mentioned SEO Tools for Excel. Whatever you do, try to stay within the "white hat" principles.
Do I have to know all this?
Of course all of this is not necessary. I would be the first to hire a junior who does not know 50% of the above things, but who fits into company culture and has the motive to get better in what he does. Also, understanding the regex, HTML, and spreadsheets in Excel will not put you on the first page of Google, but it will help you to more effectively apply your SEO expertise.
Finally, these are all skills that will not become obsolete, even when the ranking algorithm is completely autonomous and based on artificial intelligence, machine learning and deep neural networks, which is a near future when SEO is in question.